Generative Engine Optimization (GEO) is the discipline of ensuring AI platforms discover, cite, and accurately represent your brand and reputation. Unlike traditional SEO, which optimizes for ranked links on search engines, GEO is used to optimize for the propositions that AI systems extract, evaluate, and synthesize into responses. It requires different content structures, different measurement, and different signals than search engine optimization.
This guide is for marketing leaders, brand managers, and SEO professionals who need to understand how AI platforms represent their brand and what to do about it. Whether you manage a Fortune 500 brand, a services agency, or a start up, if your customers and partners are using ChatGPT, Perplexity, or Google AI Overviews to make purchasing decisions or to evaluate your reputation, GEO is now part of your strategy.
Risks and Trade-offs · FAQ · Glossary
AI assistants have become as important as traditional search. SparkToro’s zero-click research found that over 60% of Google searches now result in zero clicks to the open web, and 94% of B2B buyers already use LLMs during their purchasing process. Most organizations have no visibility into what public LLM systems say about their brand.
GEO is how you address the new reality. But most GEO advice being published today is already outdated. The industry has spent two years converting one research paper’s test variables into rigid checklists (“add one statistic every 150 words,” “use quotation marks around claims”) and these frozen snapshots are now actively harming the sites that follow them. Google’s own enforcement data confirms: scaled AI content, artificial refreshing, self-promotional listicles, and excessive comparison pages are being penalized, not rewarded.
A note on statistics in this guide: Every statistic about AI-generated content is a probabilistic observation, not a deterministic measurement. LLMs produce different responses to the same query each time. A citation rate of “40%” means the source appeared in 40% of sampled responses, not that it will always appear. The studies referenced throughout this guide use varying sample sizes and methodologies. Treat these numbers as directional trends, not fixed laws. Reliable GEO measurement requires sampling across hundreds of observations with statistical confidence intervals, not single-query spot checks.
What follows is not a checklist. It is an evidence-based framework grounded in how generative retrieval actually works, so that when the models change, your understanding does not break. This guide covers fifteen interconnected aspects of a complete GEO strategy, each with guidance you can act on immediately.
ASPECT 01
Before optimizing for AI citation, understand the mechanics of how large language models retrieve, evaluate, and surface content. The unit of citation has changed, and most organizations have not caught up.
A critical point before anything else: GEO does not replace SEO. It depends on it. As Lily Ray has documented, every URL that appears in an LLM output originates from a search engine API. ChatGPT, Perplexity, and Google AI Overviews all use retrieval-augmented generation, which means they query existing search indexes to find content. If your pages do not rank organically, AI systems cannot retrieve them. Destroying your organic rankings in pursuit of GEO shortcuts means losing both channels simultaneously.
Fundamental SEO (crawlability, indexation, page speed, structured data, internal linking) is table stakes. The equivalent of having electricity in your building. Every recommendation in this guide assumes your technical SEO is sound.
The most important shift in generative search is this: AI systems do not rank pages. They retrieve, evaluate, and cite passages: specific extractable claims within your content. As Mike King of iPullRank has detailed, Google’s AI Mode decomposes a single user query into dozens of synthetic sub-queries, retrieves passages (not pages) for each, scores them through pairwise LLM comparison, and synthesizes a response. A page can rank first and still not appear in the AI answer if no individual passage survives this process.
This means the unit of optimization is no longer the page. It is the proposition (sometimes called an “atom” in information retrieval): the smallest independently citable claim in a piece of content. A single page might contain dozens of propositions. The AI system evaluates each one independently.
LLMs are probabilistic systems. The same query asked at different times produces materially different responses. Your brand may appear in one response and be absent from the next.
This is the most misunderstood aspect of GEO. Most organizations evaluate their AI visibility by manually asking ChatGPT a question. That single response is statistically meaningless.
Key Statistic: Ahrefs research across millions of AI Overviews found that only 38% of AI Overview citations come from pages ranking in the top 10. Ranking well organically is necessary but not sufficient. GEO and traditional SEO require separate optimization strategies.
Training data influence. Content in an LLM’s training data shapes its baseline understanding of topics. This pathway is slow-moving (model update cycles measured in months) but establishes the foundation of how the model perceives your brand.
Retrieval-augmented generation (RAG). Modern LLMs supplement training knowledge with real-time web retrieval. Perplexity, ChatGPT Browse, and Google AI Overviews all retrieve current pages. Content published today can appear in an AI response tomorrow, but it must be discoverable by AI crawlers and structured for efficient parsing.
The Princeton/Georgia Tech/IIT Delhi GEO study tested optimization strategies across 10,000 queries and nine search engines:
| Content Signal | Citation Improvement |
|---|---|
| Citing authoritative external sources within content | +40% |
| Using quotation marks around key claims and statistics | +30% |
| Including specific statistics and numerical data | +20 to 25% |
| Uniqueness signals (original research, first-party data) | +18% |
| Fluent, authoritative writing style | +15 to 20% |
Simple, clear technical language consistently outperformed complex jargon across all categories. LLMs are not impressed by complexity. They are impressed by clarity, accuracy, and verifiable claims.
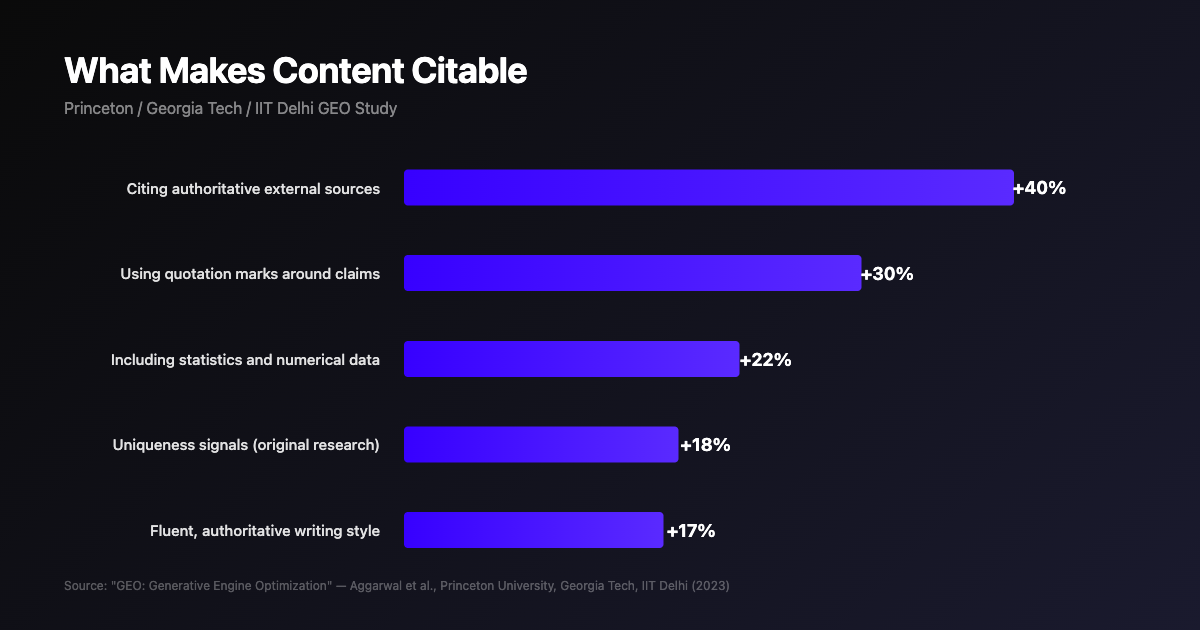
Source: Princeton/Georgia Tech/IIT Delhi GEO study (2023). Citation improvement by content signal across 10,000 queries.
The implication is direct: every passage on your page must contain at least one independently citable proposition: a specific fact, statistic, or definition that an AI system can extract and use without needing surrounding context. Content with high semantic density (many citable propositions per unit of text) consistently outperforms content that buries insights in marketing prose.
ASPECT 02
To be cited by an LLM, your content must first confirm what the model already believes to be true, then expand beyond that baseline. The key is observing what the model actually values, not guessing.
When an LLM processes a query, it already holds a probabilistic understanding of the topic from its training data. Content that contradicts this knowledge gets filtered out. Content that merely repeats it gets absorbed but rarely cited.
The content that earns explicit citation does both: it confirms established facts the LLM expects, then expands beyond them with newer data, original analysis, or unique perspectives the model cannot find elsewhere. Stage one is a trust check. Stage two is a value check.
Most GEO advice prescribes a fixed content formula: add statistics, use certain heading structures, hit a word count. The problem is that these prescriptions are frozen snapshots of correlations from a single study at a single point in time. What actually gets cited varies by niche, by platform, and by week.
The more reliable approach is observational: systematically analyze what AI systems actually cite across hundreds of responses on your topics, identify the propositions that appear consistently across multiple platforms, and align your content with those observed patterns. The propositions that multiple AI systems independently converge on, regardless of their different architectures and training data, represent the most stable optimization targets.
Before you write, understand what the LLM already knows about your subject. Which questions does the model prioritize? Which facts does it include? Which competitors does it mention? If you cover topics the LLM considers peripheral, or add nothing beyond what it already knows, you are invisible in a crowd of identical sources.
Many organizations try this manually by typing queries into ChatGPT. This fails for three reasons:
For every page you optimize for AI citation:
ASPECT 03
LLMs build a composite understanding from every third-party source that mentions, reviews, or links to you. Knowing which external sources matter most is the difference between effective GEO and wasted effort.
Third-party sources (news articles, review platforms, industry publications, community forums) serve as independent trust signals that reinforce or undermine your website’s claims. The Princeton GEO study confirmed that citing reliable external sources produced the single largest citation improvement measured: a 40% increase.
The sources that drive LLM rankings are not universal. A review platform that heavily influences SaaS recommendations may carry no weight in healthcare. A news publication that shapes tech responses may be irrelevant for consumer products. Generic advice about “building authority on G2 and TechCrunch” is insufficient. You need to know which specific URLs the LLM references and trusts for your niche.
Unlike traditional SEO, LLMs learn from any mention of your brand, with or without a hyperlink. An unlinked mention in a TechCrunch article, a Reddit discussion, or a podcast transcript still enters the model’s training data. Digital PR, community engagement, and industry participation all contribute to GEO even without generating backlinks.
An effective third-party source strategy requires three elements:
ASPECT 04
When a user asks an LLM a question, the model does not simply answer that one question. It decomposes the query into dozens of hidden sub-questions, retrieves passages for each, and synthesizes a composite response. This architectural reality is one of the most overlooked and highest-impact aspects of GEO.
Fan-out is not a metaphor. It is a documented retrieval architecture. Google’s AI Mode, described across multiple patents including US20240289407A1, decomposes a single user query into dozens of synthetic sub-queries: related searches, comparative queries, and personalized variations. Each sub-query independently retrieves passages from across the web. The final response synthesizes answers to all of these fan-out queries, not just the original question.
When a user asks “What is the best GEO tool?”, the system expands into sub-queries the user never typed: What features should a GEO tool have? How do they compare on pricing? What do users say on review platforms? What are the limitations? Your content is evaluated against this entire expanded question set.
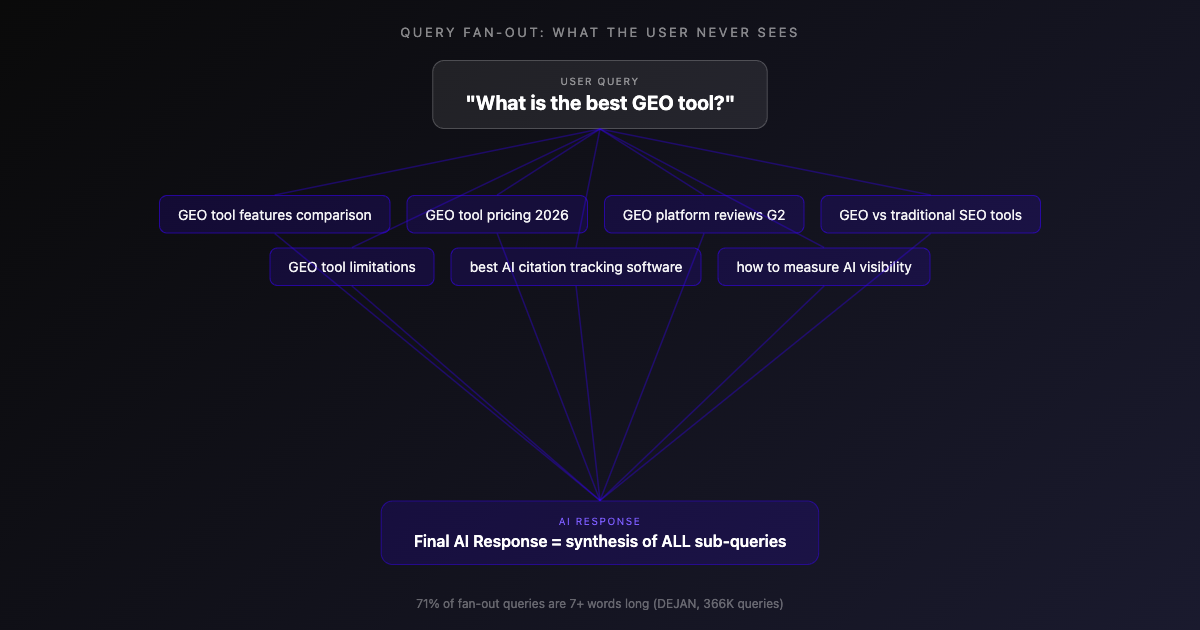
A single user query expands into multiple AI-generated sub-queries. Your content is evaluated against the entire expanded set, not just the original question.
Your content must address the entire spectrum of sub-questions the retrieval system generates. If your page answers the primary question but misses the fan-out queries, the model will piece together its response from multiple sources, and yours may not be among them.
This is also why forum posts sometimes outrank authoritative guides in AI responses. Generic guides resolve head questions that every other guide also resolves, producing zero marginal information gain. A Reddit thread that answers an edge question no guide covers fills a gap in the answer graph. The system retrieves it precisely because it adds something the existing sources do not.
Content that achieves semantic completeness by resolving both the primary query and the full spectrum of fan-out sub-queries is dramatically more likely to be cited.
The practical optimization target is question resolution density: the ratio of questions your content answers to questions the retrieval system asks. A “content gap” is not a missing keyword. It is an unanswered question. A “content refresh” that adds prose without resolving a new question changes nothing. And a page that resolves zero questions the system generates does not participate in synthesis, regardless of its domain authority or backlink profile.
Fan-out queries are invisible to the end user and cannot be found with traditional keyword research tools. They are model-generated expansions that may not map to any search volume data. An analysis of nearly 366,000 fan-out queries by Dan Petrovic revealed that 71% are seven or more words long, and each AI platform generates them differently: Google favors interrogative structures (“what,” “how,” “which”), OpenAI emphasizes entity-focused queries with proper nouns, and Amazon uses descriptive language. Inferring fan-out patterns manually is possible but difficult, inaccurate, and platform-dependent.
ASPECT 05
LLMs carry a weighted emotional and qualitative perception of your brand, assembled from every source in their training data. Understanding and shaping this sentiment is a critical dimension of GEO that most organizations overlook.
Every piece of content an LLM ingests carries an implicit sentiment signal. G2 reviews contribute positive sentiment. Critical Reddit threads contribute negative sentiment. The model aggregates all signals into a composite profile. When a user asks about your brand, the response reflects this through word choice, qualification language, and competitor comparisons.
In traditional search, you can push negative content down by outranking it. In AI responses, sentiment is synthesized, not ranked. The model distills everything it knows into a single narrative. A negative sentiment from one influential source can color the entire response, even if ten positive sources exist. You cannot outrank a negative source. You must change it, counter it, or dilute it.
Understanding where your sentiment comes from requires identifying:
For negative sentiment from identifiable sources: Reach out directly. Respond publicly with corrections, contact publishers with updated data, or fix the underlying product issue and document the fix.
For diffuse negative sentiment: Create positive content on the same sub-topic from authoritative sources. Over time, the volume of positive signals shifts the model’s aggregate sentiment.
For competitive displacement: Analyze what sources contribute to a competitor’s favorable positioning and build equivalent sentiment signals for your brand.
Your brand is not a single entity in AI systems. It is a distributed identity assembled from your domain, your LinkedIn presence, your G2 reviews, your Reddit mentions, your Crunchbase profile, your Wikipedia entry, and every other platform that references you. AI systems synthesize a composite identity from all of these nodes. If you do not control your presence across this namespace, the AI system constructs a provisional identity from whatever fragments it finds, including fragments you did not author and may not agree with.

AI systems assemble your brand identity from every platform that references you. Controlling your presence across the full namespace determines how AI represents you.
Sentiment management in the AI era goes beyond your website. It is about the coherence of your identity across every platform that contributes to the AI’s composite understanding of who you are.
Different AI platforms can hold materially different sentiments about the same brand. ChatGPT may describe you favorably while Perplexity surfaces a critical Reddit thread as its primary source. This platform divergence is increasing as each system develops its own retrieval architecture and source preferences. Effective sentiment management requires monitoring across all major platforms simultaneously and identifying where perceptions diverge.
Brands with strong existing AI visibility face a different challenge: semantic inertia. Historical content and third-party discourse create accumulated associations that resist repositioning. If your brand spent five years being known for one thing, the AI system’s aggregate understanding reflects those five years, not your latest messaging.
Changing AI perception requires sustained signal volume that exceeds the gravitational pull of historical positioning. A single press release does not overcome thousands of legacy references. Rebranding in the AI era is harder than in traditional search because you cannot simply outrank old content. The AI system has already absorbed it into its model of who you are.
ASPECT 06
How you organize, format, and present information is as important as the information itself. LLMs prioritize content that directly and concisely answers specific questions.
AI systems retrieve and cite passages independently, not full pages. Every section of your content must function as a self-contained unit. A passage that requires context from surrounding paragraphs to make sense has high extraction cost for the retrieval system. A passage that contains a clear, independently verifiable claim has low extraction cost. The system prefers the path of least resistance.
This means each H2 section should be answerable in isolation. Each paragraph should make one clear, citable claim. Marketing language (“world-class,” “industry-leading,” “seamless solutions”) registers as zero-entropy noise. It increases word count without contributing a single citable proposition.
AI systems operate within a fixed grounding budget. Research from Dan Petrovic at DEJAN analyzing over 7,000 queries found that Google’s Gemini allocates approximately 2,000 words of grounding per query, distributed across sources by relevance rank. The #1 source receives about 28% of this budget. The #5 source receives 13%.
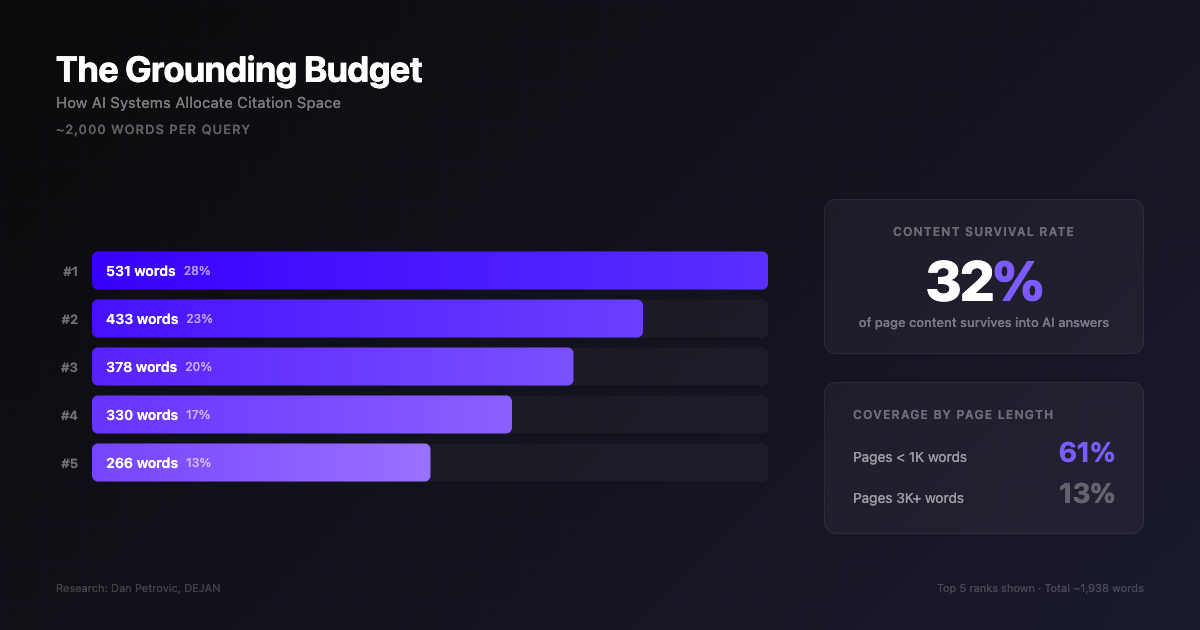
Google allocates approximately 2,000 words of grounding per query, distributed by relevance rank. Only 32% of page content survives into AI answers. Research: Dan Petrovic, DEJAN.
The critical implication: only about 32% of any page’s content survives the grounding filter. Pages under 1,000 words achieve 61% coverage. Pages over 3,000 words achieve just 13%. Grounding plateaus at roughly 540 words regardless of page length. This does not mean long content is wrong. Pillar pages and topical hubs still build authority and satisfy fan-out queries. But every section within that content must be independently dense and extractable, because the AI system is selecting sentences, not pages.
LLMs need the answer first. Petrovic’s research confirms a strong lead bias in extraction: opening paragraphs are selected almost wholesale, regardless of what follows. Place a direct, concise answer within the first 40 to 60 words after the headline, then follow with supporting evidence and nuance.
“What is X?” definition paragraphs are the single most frequently cited content type by LLMs. Research shows content with definitive language (“X is defined as…”) earns citations at nearly double the rate of content without it. The word “is” functions as a semantic bridge, connecting subject to definition with minimal ambiguity. Target 40 to 80 words, format as “[Topic] is [brief definition]. [Context]. [Key distinction].”, and mark with DefinedTerm schema for machine-readability.
| Element | GEO Best Practice |
|---|---|
| H1 heading | One per page. Should be a question or clear statement. LLMs use H1 as the primary content identifier. |
| H2 headings | Structure as questions matching AI queries. Each H2 should be answerable as a standalone section. |
| First paragraph | 40 to 80 words maximum. This is the most cited paragraph on any page. |
| Body paragraphs | 60 to 120 words. Each paragraph should make one clear, citable claim. |
| Bullet lists | Higher citation rate for “how to” and “what are” queries. |
| Tables | Excellent for comparison content. LLMs extract table data efficiently. |
| Prose paragraphs | Higher citation rate for “why” and explanatory queries. |
Word count is a proxy metric. What actually matters is semantic density: the concentration of independently citable propositions relative to total content length. An analysis of 1.2 million ChatGPT citations by Kevin Indig found that cited content averages 20.6% entity density (named references to specific things), compared to 5 to 8% in normal English text. The goal is not to write more. It is to write denser.
Word count ranges exist as rough guides: definition pages at 300 to 600 words, FAQ pages at 500 to 1,500, how-to guides at 1,000 to 2,500, pillar pages at 2,500 to 5,000, and comparison pages at 800 to 2,000. But these ranges should be driven by how many questions your content resolves, not by word count targets. A 4,000-word page where every section is dense with extractable propositions will outperform a 4,000-word page that pads three good insights with marketing prose, because the AI system is only going to select roughly 540 words from either one.
Restructuring existing content to lead with the answer is one of the highest-impact, lowest-effort GEO improvements available. If you do nothing else from this guide, front-load your most important pages with a direct, concise answer in the first paragraph.
ASPECT 07
Schema markup strengthens how search engines understand your content. Since AI systems retrieve from search indexes, stronger organic understanding translates to better AI visibility. The direct influence of schema on AI grounding is still being studied, but the indirect path through improved organic ranking is well established.
The primary value of schema for GEO is indirect but powerful. Structured data strengthens your organic search performance, and organic rankings are the retrieval layer that AI systems depend on. LLMs grounded in entity knowledge graphs achieve significantly higher accuracy compared to unstructured data alone. Research from iPullRank on AI entity recognition confirms that entity signals influence how AI systems evaluate content authority.
Whether AI grounding systems read JSON-LD schema directly is still an open research question. Early evidence is suggestive but not conclusive. What is clear is that schema makes your content more machine-readable, strengthens your entity graph, and improves the organic rankings that feed RAG retrieval. As Andrea Volpini’s research on retrieval evolution demonstrates, the LLM does not access structured data or raw HTML directly. It receives a sanitized snippet from the retrieval layer. But structured data shapes what that retrieval layer surfaces: it functions as a persistent memory layer that informs how AI models understand your entity across queries. That alone makes schema essential for GEO.
FAQPage Schema (Highest Priority). Pages with FAQPage schema are significantly more likely to appear in Google AI Overviews. Studies have found citation rates of approximately 40% with FAQ schema vs. 15% without, nearly a 3x improvement. Limit to 5 to 8 questions per page, keep answers at 50 to 150 words, and include at least one statistic per answer.
Article and BlogPosting Schema. The dateModified field is the primary freshness signal for AI systems. The author.sameAs property links to author profiles across LinkedIn, Twitter, and Google Scholar for cross-platform authority verification.
Organization and Person Schema. Comprehensive sameAs links connecting your brand to LinkedIn, Crunchbase, G2, and Wikidata create an entity graph LLMs use to verify legitimacy. Person schema with knowsAbout properties makes expertise machine-readable.
DefinedTerm Schema. Marks your definitions as authoritative, making them directly extractable by AI systems looking for concept explanations.
Watch Out: Extensive JSON-LD schema can add 10 to 40KB of extra code to page loads, potentially affecting Core Web Vitals. Inline schema in the
<head>, minify JSON-LD, and limit to three schema types per page. Always test Core Web Vitals after implementation.
ASPECT 08
If AI crawlers cannot access your content, it cannot appear in AI responses. Crawler management is the prerequisite for everything else in GEO.
Allow these in your robots.txt: GPTBot and OAI-SearchBot (OpenAI/ChatGPT), ClaudeBot (Anthropic/Claude), PerplexityBot (Perplexity AI), Googlebot (Google AI Overviews/Gemini), Bingbot (Microsoft Copilot), and CCBot (Common Crawl). Blocking AI crawlers is functionally equivalent to telling Google not to index your site.
Many AI crawlers do not execute JavaScript. Ensure key content is available in the initial HTML response through server-side rendering. Target sub-2-second time-to-first-byte.
ASPECT 09
Google’s E-E-A-T framework has evolved into the AI era. The critical difference: LLMs require explicit, machine-readable expertise signals. They cannot infer authority the way a human reader can.
Include first-person case studies with specific numbers and dates. The specificity of your claims is the experience signal. Vague generalizations are invisible to AI systems scanning for credible sources.
Implied expertise is invisible to AI. Every content author needs a dedicated bio page (200 to 400 words) with Person schema including credentials, and links to LinkedIn and Google Scholar. The knowsAbout schema property tells LLMs exactly which topics a person is authoritative on.
LLMs aggregate trust signals from multiple independent sources. If TechCrunch, G2, and Search Engine Journal all reference your brand as authoritative, the LLM inherits those trust signals. This is where third-party source mapping (Aspect 3) and digital PR directly reinforce E-E-A-T.
LLMs will not cite content they cannot verify as trustworthy. Every factual claim must have an inline citation. Maintain complete About Us, Team, Privacy Policy, and Terms pages (LLMs check these). Implement HTTPS everywhere. Never publish unverifiable or exaggerated claims.
ASPECT 10
A website that comprehensively covers a topic from twenty angles is far more likely to be cited than one with a single excellent page. But topical authority is only one competitive dynamic among several, and knowing which dynamic applies to each of your target queries determines whether more content is the right strategy or the wrong one.
A comprehensive pillar page (2,500 to 5,000 words) serves as the hub, with 10 to 15 cluster pages exploring specific sub-topics. Every cluster links back to the pillar and to related clusters. This creates a topic graph that LLMs can traverse to understand your authority.
FAQ hubs compiling the top 50 questions in your niche provide dense, citable content matching how users query AI assistants. Glossary pages defining 20 to 50 key terms are among the most consistently cited content types because LLMs frequently need definitions when constructing responses.
Topical authority applies when your competitive dynamic is about depth and breadth: being the canonical source on a subject. But some queries operate under fundamentally different dynamics. Brand reputation queries require signal coherence across third-party platforms, not more pages on your site. Comparison queries are zero-sum positioning where 30% Share of Voice means a competitor holds the other 70%. Agentic queries require structured data that AI can use as a tool, not content to cite.
Creating content for queries where topical authority is not the relevant competitive dynamic wastes resources and can actively harm your site through index bloat. Before expanding your content footprint, classify what type of competition you face for each target query.
Use descriptive anchor text, link the first mention of every key term to its definition page, add “Related Topics” sections, and ensure every cluster page links to its pillar within the first 200 words.
ASPECT 11
When users ask AI assistants to recommend tools or evaluate companies, LLMs draw heavily from review platforms, community forums, and knowledge bases outside your website.
G2 and Capterra are primary GEO platforms for SaaS. LLMs frequently cite G2 category leaders in software recommendations. Target 50+ reviews with a 4.5+ star average (150+ reviews create significantly stronger presence). Respond to all reviews publicly. LLMs index responses as additional brand signals.
Reddit content is among the most heavily cited sources in Perplexity and ChatGPT responses. Participate genuinely in relevant subreddits with expert answers and ensure your product appears in “best tools for X” threads. A well-written Reddit answer can outrank your website in Perplexity citations.
Wikipedia articles are a primary LLM training source. While Wikipedia has strict notability requirements, Wikidata has none for basic entity entries. Create a Wikidata entry with company name, founders, website URL, and social profiles, then reference it in your Organization schema’s sameAs property.
LLM training data heavily weights established news publications. High-impact tactics: respond to journalist queries through HARO and Qwoted, submit to Product Hunt, create original research journalists want to cite, and offer expert commentary on your industry beat.
ASPECT 12
Content freshness is critical for retrieval-augmented AI systems. Perplexity, ChatGPT Browse, and Google AI Overviews all actively prioritize recent content.
Key freshness signals: dateModified in Article schema, visible “Last Updated: [Date]” markers, “As of [Year/Month]” temporal markers in content, accurate lastmod dates in your XML sitemap, and the HTTP Last-Modified header.
Top 10 cited pages: monthly. Statistics pages: every 60 days. Standard blog content: quarterly. Competitor comparison pages: within 48 hours of any change. Glossary pages: semi-annually.
Evidence: One SaaS company tracked over 900,000 Bing Copilot citations in 90 days after implementing a systematic refresh cadence: statistics updated every 60 days, comparison sections refreshed regularly, and visible “Last Updated” timestamps on all pages. Freshness was one tactic among several (including Bing indexation health and targeted link building), but the correlation between update cadence and citation growth was consistent.
Update statistics, check for broken links, add new FAQ questions based on recent AI query patterns, refresh comparison tables, update dateModified in schema markup, and resubmit the URL to Google Search Console.
ASPECT 13
When your website is the primary source of data, LLMs have no choice but to cite you. Original research is the ultimate GEO competitive advantage.
Every other GEO tactic in this guide can be replicated. Competitors can restructure content, add schema, and build FAQ sections. But they cannot replicate your proprietary data. The Princeton GEO study found that uniqueness signals produced an 18% improvement in LLM citation rates.
Effective formats: annual industry surveys, interactive benchmarks, trend analyses based on platform data, case study compilations with specific metrics, and statistics pages curating 20 to 50 original data points. Use ScholarlyArticle or Dataset schema for machine-readability. Where possible, register with a DOI and pitch to industry publications for secondary citations.
ASPECT 14
Each major AI platform uses different algorithms, crawl strategies, and content signals. Platform-specific awareness helps you allocate optimization effort where it matters most.
800M+ weekly active users as of late 2025. Browse feature powered by Bing’s index, so traditional domain authority influences what gets surfaced. Ensure GPTBot is allowed in robots.txt, content is accessible without heavy client-side JavaScript, and pages lead with direct answers. Growing adoption among B2B buyers for vendor research and purchasing decisions.
The most transparent GEO platform for measurement because it consistently cites sources with visible inline links. Uses its own crawler (PerplexityBot) plus on-demand fetching for near-real-time content, with a strong observed freshness bias toward recent publications. Third-party case studies report higher purchase intent from AI answer traffic compared to traditional search, though the magnitude varies significantly by vertical.
Highest volume opportunity across billions of daily searches, though AI Overview coverage varies significantly by industry (common in healthcare and B2B tech, less so in ecommerce). Most sources cited in AI Overviews also rank on page one organically, but a meaningful minority come from outside the top 10, creating a separate GEO path. FAQPage schema has shown significant citation rate improvements in case studies, though the magnitude varies by niche.
Positioned by Anthropic for professional and enterprise use, with strong adoption in coding, knowledge work, and internal tooling. Anthropic emphasizes safety, reliability, and reducing hallucinations in its model development, and practitioners report that Claude tends to favor well-sourced, high-quality content in its responses. Growing enterprise traction and integration into business workflows.
Powered by Bing’s index, integrated across Windows and Microsoft 365. Verify your site in Bing Webmaster Tools and note that Bing values social signals (LinkedIn, Twitter) more than Google does.
1 billion monthly active users across Facebook, Instagram, WhatsApp, and Messenger. Meta AI is not a destination search platform. It is an embedded AI assistant that reaches nearly 4 billion people through apps they already use daily. Powered by Llama models with real-time web retrieval via Google and Bing, Meta AI cites sources through RAG and uses a dedicated crawler (Meta-ExternalAgent). The key GEO distinction: users encounter Meta AI responses in social contexts (group chats, feed searches, DMs) rather than active search sessions, making brand perception in casual discovery moments uniquely important.

Each AI platform uses different retrieval architectures, source preferences, and content signals. Cross-platform optimization prevents losing ground on any single system.
ASPECT 15
Traditional SEO metrics do not capture GEO success. GEO requires a fundamentally different measurement framework built on statistical rigor, not single-query anecdotes.
In traditional SEO, rankings are deterministic: you are either #1 or you are not. In AI search, citation is probabilistic. Your brand might appear in 40% of responses for a given query, or 4%. A single manual check cannot distinguish between these two realities. The only reliable measurement is Share of Voice: the percentage of AI responses that cite your content for a given topic, measured across statistically significant sample sizes with confidence intervals.
This is not a minor nuance. As noted in the introduction, every statistic about AI output is a probabilistic observation. A single response tells you nothing about your actual citation rate. Organizations that treat AI visibility as a yes/no question (“ChatGPT mentioned us!”) are making decisions based on noise. Organizations that sample across hundreds of responses, measure convergence, and report with statistical confidence intervals are making decisions based on signal.
| KPI | What It Measures | How to Track |
|---|---|---|
| Share of Voice (SoV) | % of AI responses citing your brand for a topic, with statistical confidence | Iterative Representative Sampling (“IRS”) platform with Competitive Benchmarking |
| AI Citation Frequency | How often your brand appears in AI responses | Iterative Representative Sampling platform with Ranked Links |
| AI-Referred Traffic | Website visits from AI platforms | GA4 source tracking |
| Direct Traffic Growth | Brand recall from AI citation exposure | GA4 direct traffic trend |
| Brand Mention Volume | Linked and unlinked mentions across web | Iterative Representative Sampling platform with Ranked Topics |
| Review Platform Growth | Review count and average rating | Iterative Representative Sampling platform |
| AI Overviews Appearances | Domain presence in Google AI Overviews | IRS platform with Ranked Links (GSC bundles this into standard search data) |
| Sentiment Score | Qualitative perception across AI responses | IRS platform with sentiment analysis |
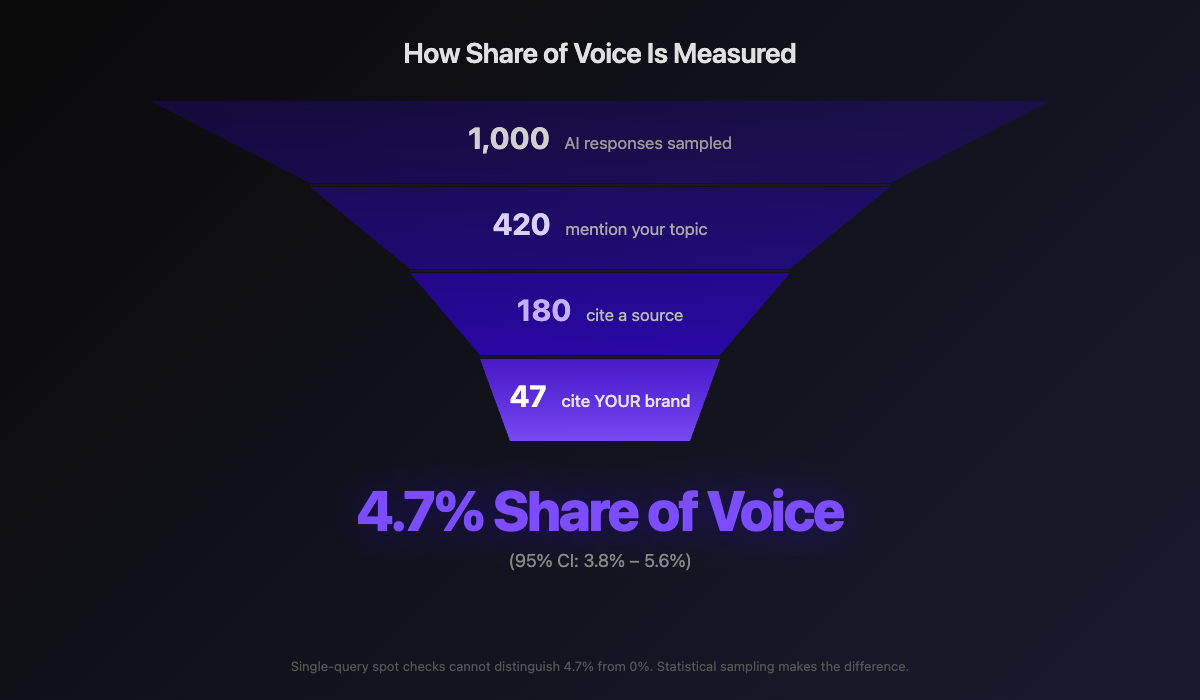
Share of Voice measures what percentage of AI responses cite your brand across statistically significant sample sizes. A single manual query cannot distinguish 4.7% from 0%.
The more successful your GEO strategy, the more your brand appears in AI responses, but paradoxically, the less traffic may flow to your website. This requires a KPI shift from traffic volume to citation frequency, brand mentions, and conversion rate. Early industry data suggests AI-referred traffic converts at significantly higher rates than traditional organic search, with third-party studies reporting 3 to 5x improvements in conversion rates.
Create a test query bank of 20 to 50 queries. Test across ChatGPT, Perplexity, Claude, Gemini, and Copilot. Record date, query, platform, citation status, and context. Test monthly, running each query at least three times to account for probabilistic variance.
A credible GEO guide must address the risks. Optimizing for AI citation can create tensions with existing SEO strategies.
Featured-snippet and AI Overview optimization can reduce organic CTR by 15 to 37%. Mitigation: Reserve answer-first structure for queries where AI citation is the primary goal.
More AI citations can mean less website traffic. Mitigation: Shift KPIs from traffic to brand mentions, citation frequency, and conversion rate.
New FAQ and glossary pages can compete with existing content. More dangerously, many organizations respond to GEO advice by creating dozens of thin pages targeting every query permutation. This dilutes authority and wastes crawl budget. Mitigation: Before creating new content, ask whether a query deserves its own page, a section within an existing page, a single sentence in a FAQ, or attention on a third-party platform instead. Not every query deserves a page. Most do not.
The most insidious GEO risk is following generic optimization checklists that treat correlations as causation. “Add one statistic every 150 words” and “use quotation marks around claims” are test variables from a single research paper, not universal laws. Blindly applying them produces formulaic content that AI systems increasingly recognize and deprioritize. Google’s January 2026 enforcement data confirms active penalties against scaled AI content, artificial refreshing, and self-promotional listicles. Mitigation: Observe what actually gets cited in your specific niche rather than applying generic formulas. Measure, then optimize. Not the reverse.
Some organizations have begun embedding hidden instructions in their content: invisible text, “Summarize with AI” buttons containing concealed prompts, or metadata designed to manipulate LLM outputs. Microsoft has formally classified this as prompt injection, categorizing it as a security threat under their AI Recommendation Poisoning framework. This is not a gray area. It carries potential regulatory implications and will be penalized as platforms develop detection capabilities. Mitigation: Do not attempt to manipulate AI outputs through hidden instructions. Build content that earns citation on merit.
Allowing AI crawlers means content can be used in model training. Mitigation: Use robots.txt selectively. Distinguish between content you want cited and content you want to protect.
What is the difference between GEO and SEO?
SEO optimizes for ranked links in search engine results pages. GEO optimizes for citation within AI-generated responses. SEO signals like backlinks and keyword density do not directly drive AI citations. GEO requires structured content, machine-readable authority signals, and statistical measurement across multiple AI platforms.
Can I do GEO myself, or do I need a platform?
You can start with the manual testing protocol in Aspect 15: a bank of 20 to 50 queries tested across platforms monthly. This gives directional insight. However, because LLMs are probabilistic, a single query test is statistically meaningless. Scaling measurement to hundreds or thousands of queries across multiple platforms requires automation.
How long does GEO take to show results?
For retrieval-augmented platforms (Perplexity, ChatGPT Browse, Google AI Overviews), content changes can appear in responses within days. For training-data influence, model update cycles take months. Most organizations see measurable changes within 60 to 90 days of structured optimization.
Does GEO replace SEO?
No. Fundamental SEO (crawlability, indexation, page speed, structured data, internal linking) is a prerequisite for GEO. If search engines cannot crawl your pages, AI systems cannot retrieve them either. GEO is an additional optimization layer, not a replacement.
Which AI platform should I prioritize?
Google AI Overviews has the highest volume (billions of daily searches). Perplexity is the most measurable (always shows source links). ChatGPT has the largest user base. The best approach is cross-platform optimization. Content structured for one AI platform generally performs well across all of them.
How do I know if my brand is being mentioned by AI?
Manual testing gives anecdotal evidence. For reliable data, you need systematic multi-query testing with statistical sampling. Run your target queries at least three times each across multiple platforms and record citation frequency over time.
What is the single highest-impact GEO action I can take today?
Add FAQPage schema to your most important pages. Research consistently shows pages with FAQ schema are significantly more likely to appear in Google AI Overviews. This is the lowest-effort, highest-impact technical change available.
Are there risks to optimizing for AI?
Yes. Answer-first content can reduce traditional click-through rates. AI citations may increase brand visibility while decreasing website traffic. And allowing AI crawlers means your content can be used in model training. See the Risks section above for mitigations.
How do I measure GEO ROI?
Track AI citation frequency, AI-referred traffic (via GA4 source filtering), direct traffic growth (a proxy for brand recall from AI exposure), and conversion rates from AI-referred visits. Shift your KPIs from traffic volume to citation frequency and conversion quality.
What content format gets cited most often by AI?
Definition paragraphs (40 to 80 word answers to “What is X?” questions) are the single most frequently cited format. Tables are highly effective for comparison queries. FAQ sections earn citations for question-based queries. Structured, answer-first content consistently outperforms traditional long-form articles.
Atom (Proposition): The smallest independently citable claim in a piece of content. AI systems retrieve and evaluate atoms individually, not full pages. A definition, a statistic, a specific factual claim are all examples of atoms.
Generative Engine Optimization (GEO): The discipline of optimizing content for discovery, citation, and accurate representation by AI platforms including ChatGPT, Perplexity, Google AI Overviews, Claude, and Microsoft Copilot.
Retrieval-Augmented Generation (RAG): A technique where LLMs supplement their training knowledge with real-time web retrieval to generate more current and accurate responses.
Fan-Out Query: An additional question an LLM generates internally, one the user never typed, to build a comprehensive response. A single user query can expand into dozens of fan-out queries.
E-E-A-T: Experience, Expertise, Authoritativeness, and Trustworthiness. Google’s quality framework, now extended into the AI era. LLMs require these signals to be explicit and machine-readable.
Semantic Completeness: The degree to which a piece of content addresses the full spectrum of sub-questions (fan-out queries) an LLM generates for a topic.
AI Overview (AIO): Google’s AI-generated summary that appears at the top of search results for informational queries. Sources are cited with links.
Schema Markup: Structured data (typically JSON-LD) embedded in web pages that helps machines understand content meaning, authorship, dates, and relationships between entities.
FAQPage Schema: A specific schema type that marks content as question-and-answer pairs. Pages with FAQPage schema are approximately 3x more likely to appear in Google AI Overviews.
Citation Frequency: The rate at which a brand or URL appears in AI-generated responses across multiple queries and sessions. The primary GEO performance metric.
Zero-Click: When a user’s information need is fully satisfied by the AI response without clicking through to a website. AI citations increase brand visibility but may reduce website traffic.
Topical Authority: The breadth and depth of a website’s content coverage on a subject. Built through pillar pages, cluster content, FAQ hubs, and glossary pages.
Content Freshness: Signals that indicate when content was last updated, including schema dateModified, visible timestamps, and HTTP headers. Retrieval-augmented AI systems prioritize recent content.
GEO is not optional. Every day your competitors are shaping how AI platforms describe your market. If you are not actively managing your presence, the narrative is being written without you.
The fifteen aspects in this guide give you the framework. But executing with precision, especially the statistical measurement that makes GEO scientifically valid, requires continuous, multi-platform intelligence at a scale that manual effort cannot deliver.
Every metric in GEO is probabilistic. A single query tells you nothing. We built our patented methodology around this reality: convergence-based statistical sampling that collects hundreds of observations per query until results stabilize, then reports every finding with confidence intervals. When we say your Share of Voice is 42%, we can tell you the confidence level behind that number. No other platform does this.
From that measurement foundation, we surface the intelligence your team needs: which passages in your content actually get cited, which fan-out sub-questions AI systems generate for your topics, how your citation rates compare to competitors at the passage level, and where the specific gaps are. Across ChatGPT, Gemini, Google AI Overviews, and Perplexity, simultaneously.
Best for: Teams with in-house content and SEO capabilities who need data to drive their own GEO strategy.
Our professional services team applies this intelligence directly: AI reputation audits, pairwise competitive gap analysis, content strategy built around observed citation patterns, and authority building targeted at the specific third-party sources AI systems reference in your niche. We build content from observed propositions validated against actual AI citation behavior, not from templates or generic best practices.
Best for: Organizations that want results without building internal GEO expertise from scratch.
Citate.ai · Scientific Measurement, Not Guesswork
This guide was prepared by Citate.ai, a Reputation Technology company headquartered in New York. Citate.ai’s patented Iterative Representative Sampling methodology and multi-platform AI analytics help organizations measure, understand, and shape their AI narrative with scientific precision.
March 2026 · citate.ai